
通過本教程,你將學到樸素貝葉斯算法的原理和Python版本的逐步實現。
更新:查看后續的關于樸素貝葉斯使用技巧的文章“Better Naive Bayes: 12 Tips To Get The Most From The Naive Bayes Algorithm”
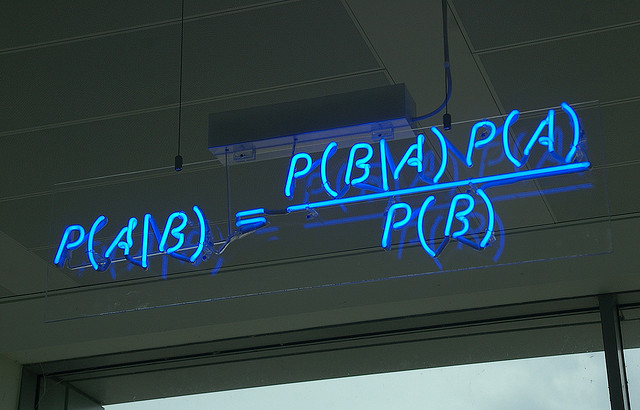 樸素貝葉斯分類器,Matt Buck保留部分版權
樸素貝葉斯分類器,Matt Buck保留部分版權
關于樸素貝葉斯
樸素貝葉斯算法是一個直觀的方法,使用每個屬性歸屬于某個類的概率來做預測。你可以使用這種監督性學習方法,對一個預測性建模問題進行概率建模。
給定一個類,樸素貝葉斯假設每個屬性歸屬于此類的概率獨立于其余所有屬性,從而簡化了概率的計算。這種強假定產生了一個快速、有效的方法。
給定一個屬性值,其屬于某個類的概率叫做條件概率。對于一個給定的類值,將每個屬性的條件概率相乘,便得到一個數據樣本屬于某個類的概率。
我們可以通過計算樣本歸屬于每個類的概率,然后選擇具有最高概率的類來做預測。
通常,我們使用分類數據來描述樸素貝葉斯,因為這樣容易通過比率來描述、計算。一個符合我們目的、比較有用的算法需要支持數值屬性,同時假設每一個數值屬性服從正態分布(分布在一個鐘形曲線上),這又是一個強假設,但是依然能夠給出一個健壯的結果。
預測糖尿病的發生
本文使用的測試問題是“皮馬印第安人糖尿病問題”。
這個問題包括768個對于皮馬印第安患者的醫療觀測細節,記錄所描述的瞬時測量取自諸如患者的年紀,懷孕和血液檢查的次數。所有患者都是21歲以上(含21歲)的女性,所有屬性都是數值型,而且屬性的單位各不相同。
每一個記錄歸屬于一個類,這個類指明以測量時間為止,患者是否是在5年之內感染的糖尿病。如果是,則為1,否則為0。
機器學習文獻中已經多次研究了這個標準數據集,好的預測精度為70%-76%。
下面是pima-indians.data.csv文件中的一個樣本,了解一下我們將要使用的數據。
注意:下載文件,然后以.csv擴展名保存(如:pima-indians-diabetes.data.csv)。查看文件中所有屬性的描述。
6,148,72,35,0,33.6,0.627,50,1 1,85,66,29,0,26.6,0.351,31,0 8,183,64,0,0,23.3,0.672,32,1 1,89,66,23,94,28.1,0.167,21,0 0,137,40,35,168,43.1,2.288,33,1
樸素貝葉斯算法教程
教程分為如下幾步:
1.處理數據:從CSV文件中載入數據,然后劃分為訓練集和測試集。
2.提取數據特征:提取訓練數據集的屬性特征,以便我們計算概率并做出預測。
3.單一預測:使用數據集的特征生成單個預測。
4.多重預測:基于給定測試數據集和一個已提取特征的訓練數據集生成預測。
5.評估精度:評估對于測試數據集的預測精度作為預測正確率。
6.合并代碼:使用所有代碼呈現一個完整的、獨立的樸素貝葉斯算法的實現。
1.處理數據
首先加載數據文件。CSV格式的數據沒有標題行和任何引號。我們可以使用csv模塊中的open函數打開文件,使用reader函數讀取行數據。
我們也需要將以字符串類型加載進來屬性轉換為我們可以使用的數字。下面是用來加載匹馬印第安人數據集(Pima indians dataset)的loadCsv()函數。
import csv def loadCsv(filename): lines = csv.reader(open(filename, "rb")) dataset = list(lines) for i in range(len(dataset)): dataset[i] = [float(x) for x in dataset[i]] return dataset
我們可以通過加載皮馬印第安人數據集,然后打印出數據樣本的個數,以此測試這個函數。
filename = 'pima-indians-diabetes.data.csv'
dataset = loadCsv(filename)
print('Loaded data file {0} with {1} rows').format(filename, len(dataset))
運行測試,你會看到如下結果:
Loaded data file iris.data.csv with 150 rows
下一步,我們將數據分為用于樸素貝葉斯預測的訓練數據集,以及用來評估模型精度的測試數據集。我們需要將數據集隨機分為包含67%的訓練集合和包含33%的測試集(這是在此數據集上測試算法的通常比率)。
下面是splitDataset()函數,它以給定的劃分比例將數據集進行劃分。
import random def splitDataset(dataset, splitRatio): trainSize = int(len(dataset) * splitRatio) trainSet = [] copy = list(dataset) while len(trainSet) < trainSize: index = random.randrange(len(copy)) trainSet.append(copy.pop(index)) return [trainSet, copy]
我們可以定義一個具有5個樣例的數據集來進行測試,首先它分為訓練數據集和測試數據集,然后打印出來,看看每個數據樣本最終落在哪個數據集。
dataset = [[1], [2], [3], [4], [5]]
splitRatio = 0.67
train, test = splitDataset(dataset, splitRatio)
print('Split {0} rows into train with {1} and test with {2}').format(len(dataset), train, test)
運行測試,你會看到如下結果:
Split 5 rows into train with [[4], [3], [5]] and test with [[1], [2]]
提取數據特征
樸素貝葉斯模型包含訓練數據集中數據的特征,然后使用這個數據特征來做預測。
所收集的訓練數據的特征,包含相對于每個類的每個屬性的均值和標準差。舉例來說,如果如果有2個類和7個數值屬性,然后我們需要每一個屬性(7)和類(2)的組合的均值和標準差,也就是14個屬性特征。
在對特定的屬性歸屬于每個類的概率做計算、預測時,將用到這些特征。
我們將數據特征的獲取劃分為以下的子任務:
按類別劃分數據
計算均值
計算標準差
提取數據集特征
按類別提取屬性特征
按類別劃分數據
首先將訓練數據集中的樣本按照類別進行劃分,然后計算出每個類的統計數據。我們可以創建一個類別到屬于此類別的樣本列表的的映射,并將整個數據集中的樣本分類到相應的列表。
下面的SeparateByClass()函數可以完成這個任務:
def separateByClass(dataset):
separated = {}
for i in range(len(dataset)):
vector = dataset[i]
if (vector[-1] not in separated):
separated[vector[-1]] = []
separated[vector[-1]].append(vector)
return separated
可以看出,函數假設樣本中最后一個屬性(-1)為類別值,返回一個類別值到數據樣本列表的映射。
我們可以用一些樣本數據測試如下:
dataset = [[1,20,1], [2,21,0], [3,22,1]]
separated = separateByClass(dataset)
print('Separated instances: {0}').format(separated)
運行測試,你會看到如下結果:
Separated instances: {0: [[2, 21, 0]], 1: [[1, 20, 1], [3, 22, 1]]}
計算均值
我們需要計算在每個類中每個屬性的均值。均值是數據的中點或者集中趨勢,在計算概率時,我們用它作為高斯分布的中值。
我們也需要計算每個類中每個屬性的標準差。標準差描述了數據散布的偏差,在計算概率時,我們用它來刻畫高斯分布中,每個屬性所期望的散布。
標準差是方差的平方根。方差是每個屬性值與均值的離差平方的平均數。注意我們使用N-1的方法(譯者注:參見無偏估計),也就是在在計算方差時,屬性值的個數減1。
import math def mean(numbers): return sum(numbers)/float(len(numbers)) def stdev(numbers): avg = mean(numbers) variance = sum([pow(x-avg,2) for x in numbers])/float(len(numbers)-1) return math.sqrt(variance)
通過計算從1到5這5個數的均值來測試函數。
numbers = [1,2,3,4,5]
print('Summary of {0}: mean={1}, stdev={2}').format(numbers, mean(numbers), stdev(numbers))
運行測試,你會看到如下結果:
Summary of [1, 2, 3, 4, 5]: mean=3.0, stdev=1.58113883008
提取數據集的特征
現在我們可以提取數據集特征。對于一個給定的樣本列表(對應于某個類),我們可以計算每個屬性的均值和標準差。
zip函數將數據樣本按照屬性分組為一個個列表,然后可以對每個屬性計算均值和標準差。
def summarize(dataset): summaries = [(mean(attribute), stdev(attribute)) for attribute in zip(*dataset)] del summaries[-1] return summaries
我們可以使用一些測試數據來測試這個summarize()函數,測試數據對于第一個和第二個數據屬性的均值和標準差顯示出顯著的不同。
dataset = [[1,20,0], [2,21,1], [3,22,0]]
summary = summarize(dataset)
print('Attribute summaries: {0}').format(summary)
運行測試,你會看到如下結果:
Attribute summaries: [(2.0, 1.0), (21.0, 1.0)]
按類別提取屬性特征
合并代碼,我們首先將訓練數據集按照類別進行劃分,然后計算每個屬性的摘要。
def summarizeByClass(dataset):
separated = separateByClass(dataset)
summaries = {}
for classValue, instances in separated.iteritems():
summaries[classValue] = summarize(instances)
return summaries
使用小的測試數據集來測試summarizeByClass()函數。
dataset = [[1,20,1], [2,21,0], [3,22,1], [4,22,0]]
summary = summarizeByClass(dataset)
print('Summary by class value: {0}').format(summary)
運行測試,你會看到如下結果:
Summary by class value:
{0: [(3.0, 1.4142135623730951), (21.5, 0.7071067811865476)],
1: [(2.0, 1.4142135623730951), (21.0, 1.4142135623730951)]}
預測
我們現在可以使用從訓練數據中得到的摘要來做預測。做預測涉及到對于給定的數據樣本,計算其歸屬于每個類的概率,然后選擇具有最大概率的類作為預測結果。
我們可以將這部分劃分成以下任務:
計算高斯概率密度函數
計算對應類的概率
單一預測
評估精度
計算高斯概率密度函數
給定來自訓練數據中已知屬性的均值和標準差,我們可以使用高斯函數來評估一個給定的屬性值的概率。
已知每個屬性和類值的屬性特征,在給定類值的條件下,可以得到給定屬性值的條件概率。
關于高斯概率密度函數,可以查看參考文獻。總之,我們要把已知的細節融入到高斯函數(屬性值,均值,標準差),并得到屬性值歸屬于某個類的似然(譯者注:即可能性)。
在calculateProbability()函數中,我們首先計算指數部分,然后計算等式的主干。這樣可以將其很好地組織成2行。
import math def calculateProbability(x, mean, stdev): exponent = math.exp(-(math.pow(x-mean,2)/(2*math.pow(stdev,2)))) return (1 / (math.sqrt(2*math.pi) * stdev)) * exponent
使用一些簡單的數據測試如下:
x = 71.5
mean = 73
stdev = 6.2
probability = calculateProbability(x, mean, stdev)
print('Probability of belonging to this class: {0}').format(probability)
運行測試,你會看到如下結果:
Probability of belonging to this class: 0.0624896575937
計算所屬類的概率
既然我們可以計算一個屬性屬于某個類的概率,那么合并一個數據樣本中所有屬性的概率,最后便得到整個數據樣本屬于某個類的概率。
使用乘法合并概率,在下面的calculClassProbilities()函數中,給定一個數據樣本,它所屬每個類別的概率,可以通過將其屬性概率相乘得到。結果是一個類值到概率的映射。
def calculateClassProbabilities(summaries, inputVector):
probabilities = {}
for classValue, classSummaries in summaries.iteritems():
probabilities[classValue] = 1
for i in range(len(classSummaries)):
mean, stdev = classSummaries[i]
x = inputVector[i]
probabilities[classValue] *= calculateProbability(x, mean, stdev)
return probabilities
測試calculateClassProbabilities()函數。
summaries = {0:[(1, 0.5)], 1:[(20, 5.0)]}
inputVector = [1.1, '?']
probabilities = calculateClassProbabilities(summaries, inputVector)
print('Probabilities for each class: {0}').format(probabilities)
運行測試,你會看到如下結果:
Probabilities for each class: {0: 0.7820853879509118, 1: 6.298736258150442e-05}
單一預測
既然可以計算一個數據樣本屬于每個類的概率,那么我們可以找到最大的概率值,并返回關聯的類。
下面的predict()函數可以完成以上任務。
def predict(summaries, inputVector): probabilities = calculateClassProbabilities(summaries, inputVector) bestLabel, bestProb = None, -1 for classValue, probability in probabilities.iteritems(): if bestLabel is None or probability > bestProb: bestProb = probability bestLabel = classValue return bestLabel
測試predict()函數如下:
summaries = {'A':[(1, 0.5)], 'B':[(20, 5.0)]}
inputVector = [1.1, '?']
result = predict(summaries, inputVector)
print('Prediction: {0}').format(result)
運行測試,你會得到如下結果:
Prediction: A
多重預測
最后,通過對測試數據集中每個數據樣本的預測,我們可以評估模型精度。getPredictions()函數可以實現這個功能,并返回每個測試樣本的預測列表。
def getPredictions(summaries, testSet): predictions = [] for i in range(len(testSet)): result = predict(summaries, testSet[i]) predictions.append(result) return predictions
測試getPredictions()函數如下。
summaries = {'A':[(1, 0.5)], 'B':[(20, 5.0)]}
testSet = [[1.1, '?'], [19.1, '?']]
predictions = getPredictions(summaries, testSet)
print('Predictions: {0}').format(predictions)
運行測試,你會看到如下結果:
Predictions: ['A', 'B']
計算精度
預測值和測試數據集中的類別值進行比較,可以計算得到一個介于0%~100%精確率作為分類的精確度。getAccuracy()函數可以計算出這個精確率。
def getAccuracy(testSet, predictions): correct = 0 for x in range(len(testSet)): if testSet[x][-1] == predictions[x]: correct += 1 return (correct/float(len(testSet))) * 100.0
我們可以使用如下簡單的代碼來測試getAccuracy()函數。
testSet = [[1,1,1,'a'], [2,2,2,'a'], [3,3,3,'b']]
predictions = ['a', 'a', 'a']
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: {0}').format(accuracy)
運行測試,你會得到如下結果:
Accuracy: 66.6666666667
合并代碼
最后,我們需要將代碼連貫起來。
下面是樸素貝葉斯Python版的逐步實現的全部代碼。
# Example of Naive Bayes implemented from Scratch in Python
import csv
import random
import math
def loadCsv(filename):
lines = csv.reader(open(filename, "rb"))
dataset = list(lines)
for i in range(len(dataset)):
dataset[i] = [float(x) for x in dataset[i]]
return dataset
def splitDataset(dataset, splitRatio):
trainSize = int(len(dataset) * splitRatio)
trainSet = []
copy = list(dataset)
while len(trainSet) < trainSize:
index = random.randrange(len(copy))
trainSet.append(copy.pop(index))
return [trainSet, copy]
def separateByClass(dataset):
separated = {}
for i in range(len(dataset)):
vector = dataset[i]
if (vector[-1] not in separated):
separated[vector[-1]] = []
separated[vector[-1]].append(vector)
return separated
def mean(numbers):
return sum(numbers)/float(len(numbers))
def stdev(numbers):
avg = mean(numbers)
variance = sum([pow(x-avg,2) for x in numbers])/float(len(numbers)-1)
return math.sqrt(variance)
def summarize(dataset):
summaries = [(mean(attribute), stdev(attribute)) for attribute in zip(*dataset)]
del summaries[-1]
return summaries
def summarizeByClass(dataset):
separated = separateByClass(dataset)
summaries = {}
for classValue, instances in separated.iteritems():
summaries[classValue] = summarize(instances)
return summaries
def calculateProbability(x, mean, stdev):
exponent = math.exp(-(math.pow(x-mean,2)/(2*math.pow(stdev,2))))
return (1 / (math.sqrt(2*math.pi) * stdev)) * exponent
def calculateClassProbabilities(summaries, inputVector):
probabilities = {}
for classValue, classSummaries in summaries.iteritems():
probabilities[classValue] = 1
for i in range(len(classSummaries)):
mean, stdev = classSummaries[i]
x = inputVector[i]
probabilities[classValue] *= calculateProbability(x, mean, stdev)
return probabilities
def predict(summaries, inputVector):
probabilities = calculateClassProbabilities(summaries, inputVector)
bestLabel, bestProb = None, -1
for classValue, probability in probabilities.iteritems():
if bestLabel is None or probability > bestProb:
bestProb = probability
bestLabel = classValue
return bestLabel
def getPredictions(summaries, testSet):
predictions = []
for i in range(len(testSet)):
result = predict(summaries, testSet[i])
predictions.append(result)
return predictions
def getAccuracy(testSet, predictions):
correct = 0
for i in range(len(testSet)):
if testSet[i][-1] == predictions[i]:
correct += 1
return (correct/float(len(testSet))) * 100.0
def main():
filename = 'pima-indians-diabetes.data.csv'
splitRatio = 0.67
dataset = loadCsv(filename)
trainingSet, testSet = splitDataset(dataset, splitRatio)
print('Split {0} rows into train={1} and test={2} rows').format(len(dataset), len(trainingSet), len(testSet))
# prepare model
summaries = summarizeByClass(trainingSet)
# test model
predictions = getPredictions(summaries, testSet)
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: {0}%').format(accuracy)
main()
運行示例,得到如下輸出:
Split 768 rows into train=514 and test=254 rows Accuracy: 76.3779527559%
聲明:本網頁內容旨在傳播知識,若有侵權等問題請及時與本網聯系,我們將在第一時間刪除處理。TEL:177 7030 7066 E-MAIL:11247931@qq.com
Copyright ? 2019-2025 m.alabama37th.com 版權所有
違法及侵權請聯系:TEL:177 7030 7066 E-MAIL:11247931@qq.com 本站由北京市萬商天勤律師事務所王興未律師提供法律服務


